Julian I. Kamil
etechcetera
Home
About me
Medium
GitHub
Mastodon
Twitter
WeChat
Blogspot
Credly
Using OpenAI GPT Models in IBM Watson Assistant
March 15, 2023 / Tags: twistech - science - technology - black hole
Tweet Using OpenAI GPT Models in IBM Watson Assistant

While OpenAI GPT models and IBM Watson Assistant provide fundamentally different methods for building AI chatbots, there are ways that we can put them together to build interesting and helpful solutions.
In this article, we’ll discuss both the similarities and differences between the two approaches and the ways that they are complementary and can be combined effectively.
GPT Models and Watson Assistant
First, the similarities.
Both technologies are using deep-learning AI models for natural language understanding that can be used to build seemingly intelligent chatbots that can converse in natural language.
GPT-4, the current generation of the OpenAI LLMs, has been integrated into Microsoft Bing Chat to provide an alternative to traditional web search, allowing users to converse with it to find information.
Watson Assistant has been implemented in various enterprises to build chatbots that often use private data sources — enterprise databases, document repositories, and APIs — to answer questions.
In both applications, the resulting user experiences are very similar: end users find what they are looking for by conversing in natural language with the chatbots. However, under the covers, they work in completely different ways to deliver that experience.
So now, the differences.
An advanced and knowledgeable autocomplete
A GPT model can be thought of as one that provides a very sophisticated form of autocomplete function. In fact, the core integration endpoint for using GPT models is simply and aptly named completions.
To use the GPT completions endpoint to generate an answer, input some text as a prompt, and it will return a text completion that most likely matches the instructions or context in the prompt. To continue having a “dialog” with the model, input the original prompt and response along with the next question to have the model produce the next answer. And so on…
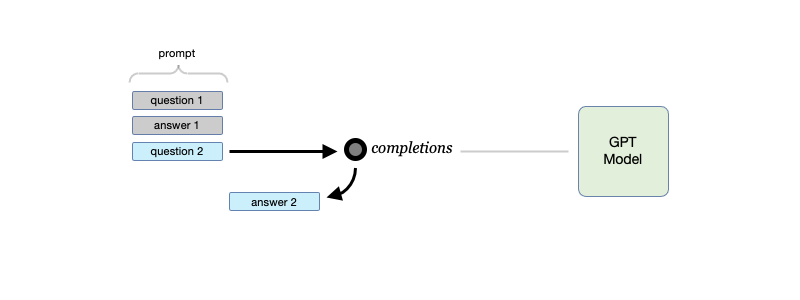
Using the completions endpoint to generate answers
GPT models can understand these prompts and can generate informative responses because they have been pre-trained with enormous amounts of carefully selected text (including text from BookCorpus, Wikipedia, Reddit, and other sources on the web) and fine-tuned by OpenAI using a technique known as RLHF (Reinforcement Learning from Human Feedback). This is how they appear to be generally intelligent and are able to provide meaningful responses.
A resolver of intents and entities
Watson Assistant works very differently from a GPT model.
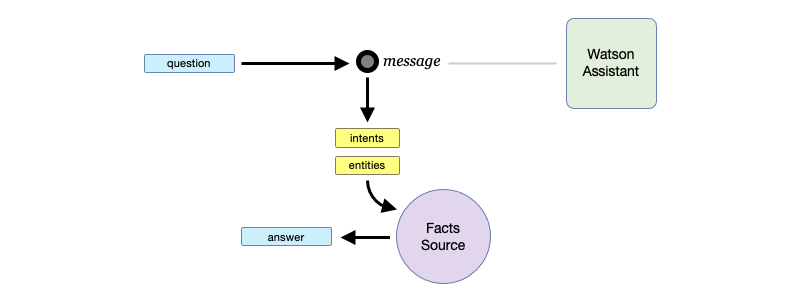
Using the message endpoint and a query to a facts source to generate answers
When a question is input into Watson Assistant’s message endpoint, it returns the intents and entities that its language model recognized in the input text. It does not generate any text completions or answers. It will be up to the caller of the endpoint to use the inferred intents and entities appropriately in order to generate correct and meaningful responses. There is no inherent general or domain-specific knowledge in Watson Assistant that can be used to readily form any intelligent or meaningful answers.
Key difference in the developer journey
Even without any fine-tuning, a GPT model can always produce an answer to every asked question using its “embedded”, pre-training knowledge. These are often very accurate and “real” answers, but at other times they are just as likely made up or hallucinated by the model.
The specific engineering of ChatGPT has made it quite compelling. But ultimately (at least until it can use outside tools) ChatGPT is “merely” pulling out some “coherent thread of text” from the “statistics of conventional wisdom” that it’s accumulated. — Stephen Wolfram, What Is ChatGPT Doing … and Why Does It Work?
Nonetheless, a GPT model can always answer any questions with confidence. A single and simple inference call is all it takes to produce an answer and complete the dialog exchange.
With Watson Assistant, work is not complete with the initial resolution of intents and entities. More work, often involving further interrogation for missing, but needed entities, or very complex queries against sources of truths is required before an answer can be produced. However, once the answer is formulated, it’s more likely to be real, precise, and accurate.
As an upside, with this approach there is no chance for any hallucinations to occur. On the other hand, to the chatbot developer, this model of integration requires a whole lot more effort to complete.
Take the best of both
There are several ways to “correct” GPT models misbehaviors and to adapt them better into specific domains.
Adding more context in the initial prompt, which with GPT-4 now can go as high as 32K tokens (about 24K words, or roughly 50 pages of printed text) is one of those methods that could get very expensive, very quickly.
Another well-known method which is cheaper, but a whole lot more complex to implement involves using embeddings of the question and searching a vector database of the domain-specific content to generate a more accurate response with a GPT model.
Ultimately, the best method to adapt a GPT model into a domain would be by fine-tuning it with additional trainings using the domain’s content.
As another alternative, we could combine Watson Assistant and a GPT model to create a question-answering chatbot that can be generally useful and less likely to hallucinate while keeping it simple enough to build.
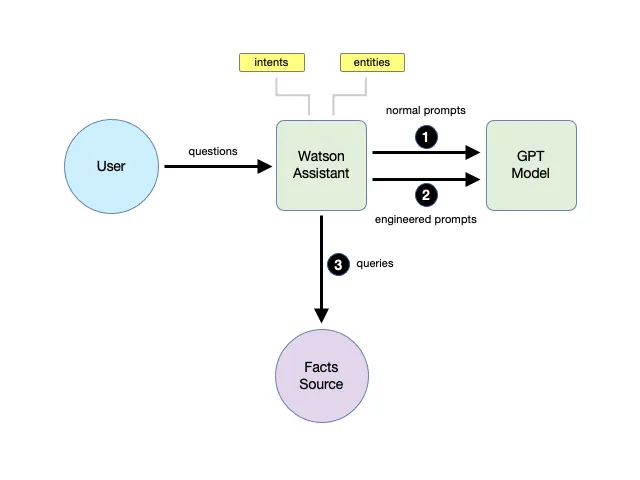
Using a GPT model in Watson Assistant
This “hybrid” method uses Watson Assistant as a front-end that can resolve the user intents and use that understanding to create a suitable prompt for the GPT model so it can generate a more factual answer. When no intents can be discerned from the query, Watson Assistant can use a more generic prompt to generate the answer. Other, more critical intents can still be handled without involving the GPT model — allowing those questions to be answered precisely and accurately.
Note: Interestingly, the newly announced Microsoft 365 Copilot System uses almost exactly this approach (termed “grounding”) to integrate GPT-powered AI features into their Office 365 suite of products. See: Explaining the Microsoft 365 Copilot System — YouTube
With this hybrid approach, the chatbot can now:
- Generate helpful answers to general questions with very little effort using the GPT model,
- Generate more factual answers to some more important questions through prompt engineering the GPT model, and
- Generate very precise and accurate answers to those questions considered the most critical by constructing them from the sources of truths.
How nice!
More articles
Share your thoughts
Using OpenAI GPT Models in IBM Watson Assistant / March 15, 2023